seq2seq
这篇论文可以看作是 sequence to sequence 论文的升级版,首先我们回顾一下 seq2seq 模型
这里 f 可以是一个 LSTM
这里 q 的运算可以是取最后一个 hidden state $h_{T_x}$
我们的目标是最大化概率:
这里面的 c 对于每一个条件概率都是一样的
在 RNN 中,上面的条件概率可以写成是:
这里面 s 是 RNN 中的 hidden state
Decoder
承接上面的我们先来研究 decoder,把 encoder 放到后面
在这篇论文中,我嗯的目标函数变成了:
条件概率是
我们发现这里面的 $c_i$ 对于每一个 RNN 循环都是不同的,$c_i$ 其实是 encoder 每一层的加权
权重是通过 softmax 得到的
每一层的 encoder 中的 $h_j$ 对于第 i 层的 decoder 的影响可以下面公式来计算
论文里面 a 的计算方式为:
Encoder
正向做一遍 RNN 得到 $(\overrightarrow{h_1},…,\overrightarrow{h_T} )$
反向做一遍 RNN 得到 $(\overleftarrow{h_1},…,\overleftarrow{h_T} )$
最后将两个得到的 hidden state 每个对应的位置拼接起来,就形成了我们想要的结果 :
Setting
- 使用 SGD 训练,minibatch 是 80 个 sentence
- 模型训练完以后,做预测的时候使用 beam search
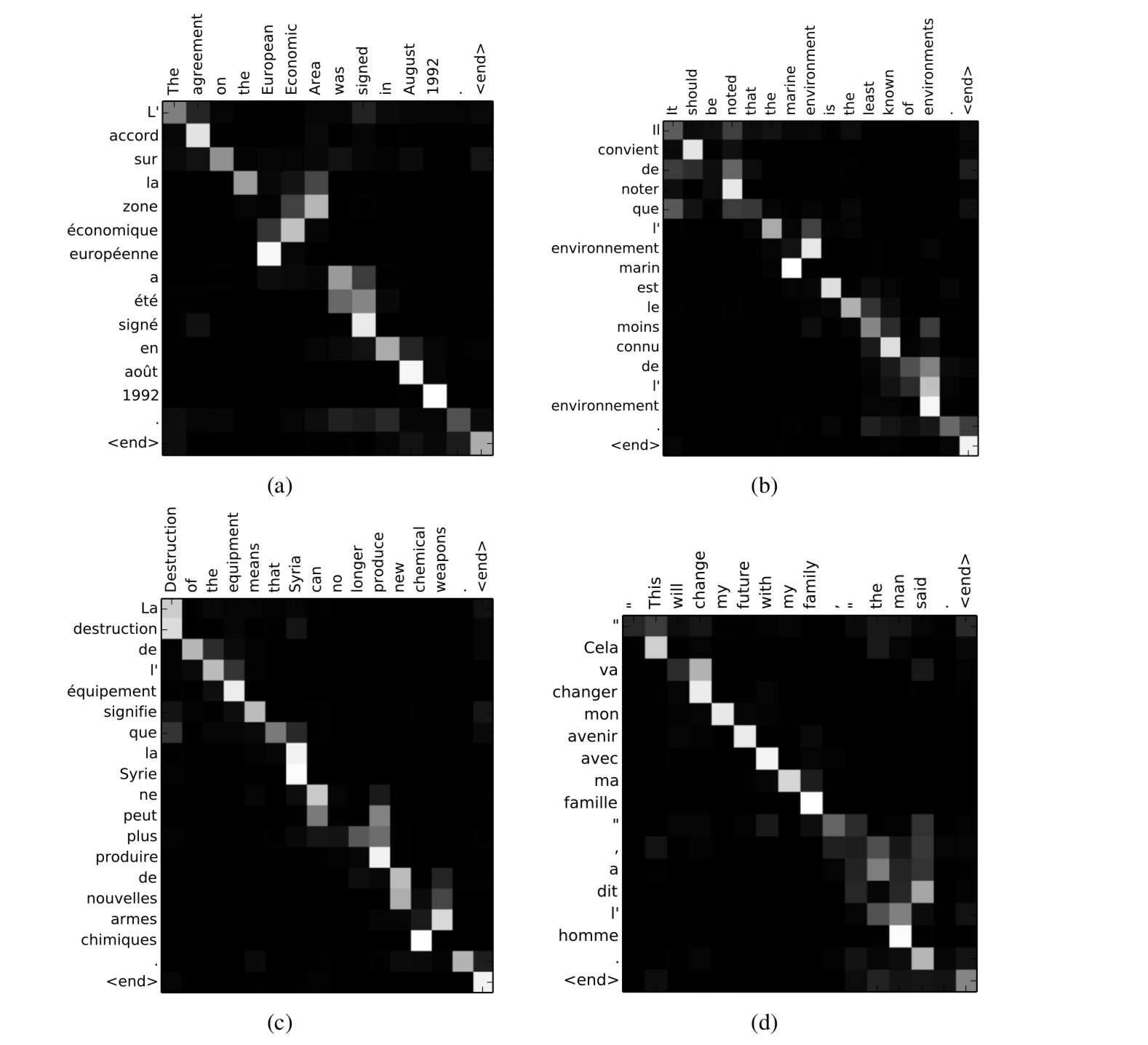
这是最后将权重可视化以后的结果,高亮区域 (i,j) 表示,输出的 $j^{th}$ 单词的和输入的 $i^{th}$ 单词关系密切
Rederence
Bahdanau, D., et al. (2014). “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473.
